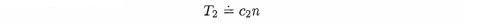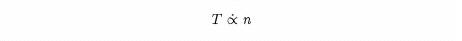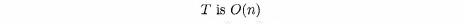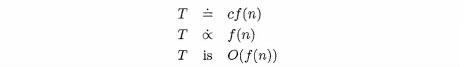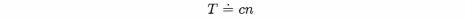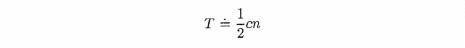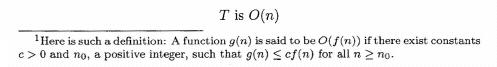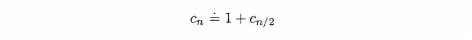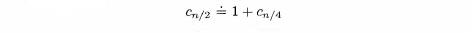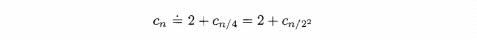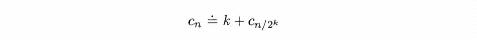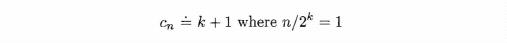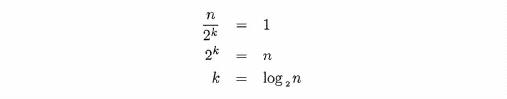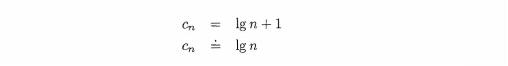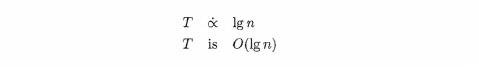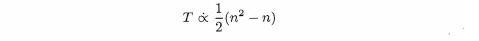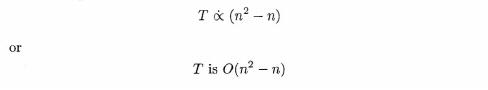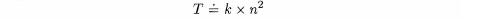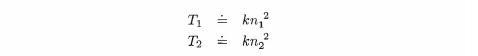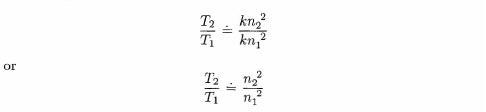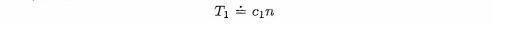
In this chapter we have looked at two searching algorithms and four sorting algorithms. We now turn our attention to the problem of comparing these algorithms, to try to decide which is "best".
Before we start comparing the efficiency of algorithms, we must agree on some way of measuring efficiency. We do not want a measure that is dependent on the language in which the algorithm is coded or on the machine on which the program is executed. Instead, we want a measure of performance that depends only on the "size" of the problem. For most problems, there is usually some clear measure of the size. For searching and sorting lists of values, the size of a problem is usually taken to be the number of elements in the list.
Once we have a measure of the size of a problem, we then want to determine how a solution to a problem grows relative to the growth in its size. To measure growth of a solution, we often compare size to either the space required by the solution or the time required by the solution. (Frequently it turns out that there is a tradeoff between these two quantities; an algorithm that is relatively fast will use more space than one that is slower.) In this text, we will not be concerned with space considerations; we will restrict ourselves to a (somewhat informal) study of growth in time relative to the growth in size of our problems.
To begin, consider the sequential search algorithm developed in the first section of this chapter. Most of the time spent by the search is devoted to comparisons between the item sought and elements of the array being searched. If there are n elements in the array, then the maximum number of comparisons that would be required is n. If, on one machine, a single comparison takes Cl time units, then, since most of the time taken by execution of the algorithm is devoted to comparisons, the total time for the search will be roughly Cl x n time units. If we let this time be Tl time units, then we have
If we change computers or programming languages, we might find that a single comparison now takes C2 time units. In this case, the total time, T2, will be given by:
In either case, the amount of time required by the sequential search is approximately proportional to n. If we let the time be T, then we could write this approximate proportionality in the form
Instead of this notation, however, we will usually write the relationship in the form
Reasonably enough, the use of 0 is called big oh notation. We can read the statement as "T is big oh of n" or "T is order n" We should confess that we are, in fact, not really telling the truth about big oh notation. More advanced courses, dealing with analysis of algorithms, give a more precise definition.1 For our purposes, however, we can think of the following relationships for a function f as being equivalent.
In making our analysis of the time required by a sequential search, we supposed that all the elements of a list would have to be examined. This is known as a worst case analysis. If we wanted to examine the average time required by a sequential search, we might make the assumption that the data are randomly ordered so that, on average, we would have to examine about half of the elements to terminate a successful search. If the worst case gave
then the average case (under our assumptions) would be
This means that T is still approximately proportional to n. Using our big oh notation, we have, once again,
Analysis of the performance of binary search requires a somewhat different approach. As with sequential search, we use the number of comparisons to obtain an approximation of the rate of growth of time, T, as the size, n, of a list increases. Again, as with sequential search, in the worst case we must continue to examine elements until the size of the list is reduced to zero. Unlike the case with a sequential search, however, each time we make a comparison with a binary search, we eliminate approximately half of the remaining items. We let the total number of comparisons required for a list of size n be Cn. Since one comparison eliminates approximately half the elements in the list, we have
Similarly
Substituting the second equation in the first gives
After one more comparison, we have
After k comparisons, we have
To actually determine the value of Cn from this equation, we note that exactly one comparison is required for a list of size one. Thus, if n/2k = 1, Cn/2k = 1 and hence
Now, to obtain Cn in terms of n, we solve the equation n/2k = 1 for k.
Because logarithms with base 2 appear so often in analysis of algorithms, we often abbreviate the expression log 2 n as simply 19 n. Substituting this value for k in our equation for cn gives us
Since the time required by the search will be roughly proportional to the number of comparisons, we have, finally
To analyze the performance of selection sort we note that, once again, the primary activity during execution of the sort is comparison of items. The first pass requires n-1 comparisons to find the largest item, the second pass requires n - 2 comparisons, the third pass requires n - 3 comparisons, and so on until the last pass requires only one comparison. The total number of comparisons is
and we know from mathematics that the sum of this arithmetic series is
As with our searches, most of the time used by selection sort is spent doing comparisons. If we let T units be the total time taken by selection sort, then
Since we are dealing here with proportionalities, we can eliminate the constant multiplier to obtain
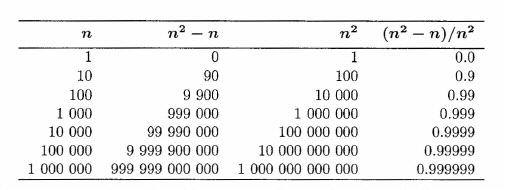
We can simplify this expression even further. To do so, let us compare values of the expression n2 - n with n2.
As you can see from the table, as ti gets larger, the effect of subtracting n from n2 becomes (in relative terms) almost insignificant. For large values of n, the expressions n2 - n and n2 are relatively very close as indicated by the ratios in the last column. In such a situation, where one term of an expression dominates any others, our big oh notation allows us to simplify our description of an algorithm's behaviour by eliminating the non-dominant terms. For the selection sort we can, therefore, write
|
|